
Dans beaucoup d’équipes produit, les retards sont d’abord analysés comme un problème de priorisation, de capacité ou d’exécution. En réalité, le frein se situe souvent ailleurs : dans tout ce qu’il faut aligner pour pouvoir avancer. Une API attendue, une validation externe, une décision non arbitrée ou une dépendance à une autre équipe suffisent à désynchroniser le delivery.
Le sujet mérite donc mieux qu’un simple suivi opérationnel. Car une dépendance n’est pas seulement un blocage à gérer : elle révèle souvent quelque chose de plus profond sur la manière dont le produit, les équipes et les décisions sont structurés.
Pourquoi les dépendances posent un vrai problème produit
On parle souvent des dépendances comme d’un sujet de delivery, presque inévitable dès qu’une organisation grandit. Pourtant, les traiter uniquement comme un problème d’exécution est réducteur. Une dépendance ne ralentit pas seulement un flux de travail : elle modifie aussi les conditions dans lesquelles une équipe peut décider, prioriser et livrer.
Lorsqu’une équipe ne maîtrise pas une partie importante de ce qui conditionne sa capacité à avancer, elle perd en autonomie. Elle dépend d’autres temporalités, d’autres arbitrages, d’autres contraintes. Cela rend le delivery moins prévisible, mais aussi les choix produit plus fragiles. Une roadmap peut sembler cohérente sur le papier et devenir beaucoup plus incertaine dès qu’on regarde ce qu’elle suppose réellement en termes de coordination.
Toutes les dépendances ne se valent pas
Le premier piège consiste à parler des dépendances comme d’un ensemble homogène. Dans la réalité, elles recouvrent des situations très différentes, qui n’ont ni les mêmes causes ni les mêmes conséquences.
Certaines sont techniques. Une équipe attend une évolution backend, l’ouverture d’une API, l’adaptation d’un composant partagé ou la stabilisation d’un système tiers. D’autres sont organisationnelles. Plusieurs équipes doivent intervenir sur un même sujet, mais sans temporalité commune, sans capacité dédiée ou sans responsabilité claire. D’autres encore sont métier ou décisionnelles : le sujet dépend d’un arbitrage, d’une validation conformité, d’une clarification juridique ou d’un accord business. Enfin, certaines dépendances sont externes et reposent sur des prestataires, des éditeurs ou des partenaires sur lesquels l’équipe a peu de prise. Les cartographier est utile, mais cela ne suffit pas. Le véritable enjeu consiste à comprendre lesquelles ralentissent réellement le flux, lesquelles peuvent être absorbées, et lesquelles révèlent un problème plus profond dans la manière de concevoir ou d’organiser le travail.
Le vrai coût d’une dépendance ne se limite pas au retard
On réduit souvent l’impact des dépendances à une question de délai. Une équipe attend, un sujet sort plus tard, la roadmap glisse. C’est vrai, mais c’est loin d’être suffisant pour comprendre ce qu’elles coûtent vraiment.
Une dépendance crée aussi de l’incertitude. Elle oblige à replanifier, à relancer, à suivre, à arbitrer, à recontextualiser. Une fonctionnalité bloquée à 90 % ne bloque pas seulement une date de livraison : elle reste ouverte dans la tête des équipes, elle mobilise du temps de coordination, elle consomme de l’attention. C’est souvent ce coût invisible qui alourdit le delivery, bien plus encore que le blocage lui-même.
Dans certaines organisations, cette accumulation devient presque structurelle. Les équipes avancent, les sprints s’enchaînent, les sujets bougent, mais la sensation de friction ne disparaît jamais vraiment. Ce n’est pas forcément un problème de niveau ou d’engagement. C’est parfois simplement le signe qu’une part trop importante du delivery dépend d’éléments extérieurs à l’équipe.
Ce que les dépendances révèlent sur votre organisation
C’est là que le sujet devient particulièrement intéressant. Car toutes les dépendances ne se résolvent pas avec un meilleur suivi, un point hebdomadaire supplémentaire ou une meilleure hygiène dans Jira. Certaines révèlent en réalité un problème plus profond : la manière dont le produit, l’architecture ou les équipes ont été découpés.
Quand une équipe ne peut presque jamais délivrer seule, quand chaque évolution traverse plusieurs couches ou plusieurs interlocuteurs, ou quand une fonctionnalité a besoin de plusieurs validations avant même de commencer à être développée, le sujet n’est plus seulement opérationnel. Il devient structurel.
Quand le problème ne vient pas du pilotage
Il est tentant de croire qu’une dépendance mal vécue est forcément une dépendance mal suivie. En pratique, ce n’est pas toujours le cas. Une équipe peut avoir identifié le blocage, l’avoir documenté, l’avoir intégré à sa roadmap, et rester tout de même prisonnière d’un système trop fragmenté.
Le problème vient alors moins de la qualité du pilotage que du nombre d’interfaces à gérer. Plus un sujet dépend de plusieurs équipes, de plusieurs couches techniques ou de plusieurs circuits de décision, plus il devient vulnérable. À partir d’un certain seuil, le meilleur suivi du monde ne compense plus la complexité du système.
Ce que le découpage des équipes change au delivery
C’est aussi pour cela que la question des dépendances ne peut pas être dissociée de l’organisation. Une équipe bien alignée sur son périmètre, disposant de responsabilités claires et d’un niveau d’autonomie suffisant, rencontrera moins de dépendances critiques qu’une équipe obligée de négocier en permanence avec son environnement.
Autrement dit, certaines dépendances ne sont pas des accidents. Elles sont la conséquence logique de la façon dont les responsabilités ont été réparties, dont les systèmes ont été construits, et dont les interfaces entre équipes ont été pensées. À ce titre, elles en disent souvent beaucoup plus sur le niveau de maturité d’une organisation que sur la qualité d’exécution d’une équipe.
Prenons un exemple simple. Une équipe produit veut lancer un dashboard temps réel très attendu côté métier. Sur le papier, le sujet paraît prioritaire : visibilité forte, valeur perçue élevée, attente interne claire. Mais dès que le cadrage commence, plusieurs dépendances apparaissent : une API backend encore instable, une équipe data à solliciter pour certains calculs, un arbitrage métier toujours en attente sur le périmètre exact de la première version, et un sujet de gouvernance sur les données affichées.
Dans ce cas, le problème n’est pas que l’équipe travaille lentement. Le problème est que le sujet traverse trop d’interfaces pour être livré simplement. Ce constat change complètement la manière de le traiter. Au lieu de pousser le projet tel quel dans la roadmap, l’équipe peut décider de réduire le périmètre, de découper une première version autonome, ou de sécuriser certaines dépendances avant d’engager tout le développement. Ce qui semblait être un simple sujet de suivi devient alors un sujet de design du delivery.
Pourquoi c’est aussi un sujet de priorisation
C’est sans doute le point le plus sous-estimé. On traite volontiers les dépendances comme un sujet de delivery, alors qu’elles ont aussi un impact direct sur les arbitrages produit.
Deux fonctionnalités peuvent avoir une valeur métier proche, voire identique, mais des conditions de delivery radicalement différentes. L’une peut être portée de manière autonome par une équipe, testée rapidement et livrée sans contrainte majeure. L’autre peut dépendre d’une équipe plateforme, d’un sujet data, d’un arbitrage juridique et d’un partenaire externe. Sur un board de priorisation classique, elles peuvent paraître comparables. Dans les faits, elles ne le sont pas du tout.
Valeur métier ne veut pas dire livrable rapidement
Une fonctionnalité très attendue peut être un mauvais pari à court terme si elle concentre trop de dépendances non sécurisées. À l’inverse, un sujet plus modeste mais beaucoup plus autonome peut permettre de générer de la valeur plus vite, avec moins d’incertitude et moins d’effort de coordination.
Cela ne veut pas dire qu’il faut toujours choisir le plus simple. Cela veut dire qu’un arbitrage produit mature ne repose pas uniquement sur la valeur attendue et l’effort estimé. Il repose aussi sur la capacité réelle d’une organisation à délivrer ce qu’elle choisit de mettre en haut de sa roadmap.
Intégrer le coût de coordination dans les arbitrages
C’est là qu’une lecture complémentaire peut devenir utile. En plus du classique impact / effort, certaines équipes gagnent à regarder les sujets sous l’angle de leur coût de coordination. Combien d’équipes faut-il aligner, combien de décisions doivent être prises, combien de zones d’incertitude restent ouvertes ? Que se passe-t-il si une seule des briques attendues prend du retard ? Cette grille change sensiblement la manière de prioriser. Elle permet de repérer les sujets à forte valeur mais trop contraints pour être lancés en l’état, ceux qui méritent d’être découpés, re-séquencés ou sécurisés d’abord. Elle aide aussi à identifier des enablers peu visibles mais structurants, parce qu’ils débloquent plusieurs sujets à la fois.
Une manière concrète d’objectiver ce sujet consiste à croiser l’impact d’une dépendance sur le delivery avec son coût de coordination.
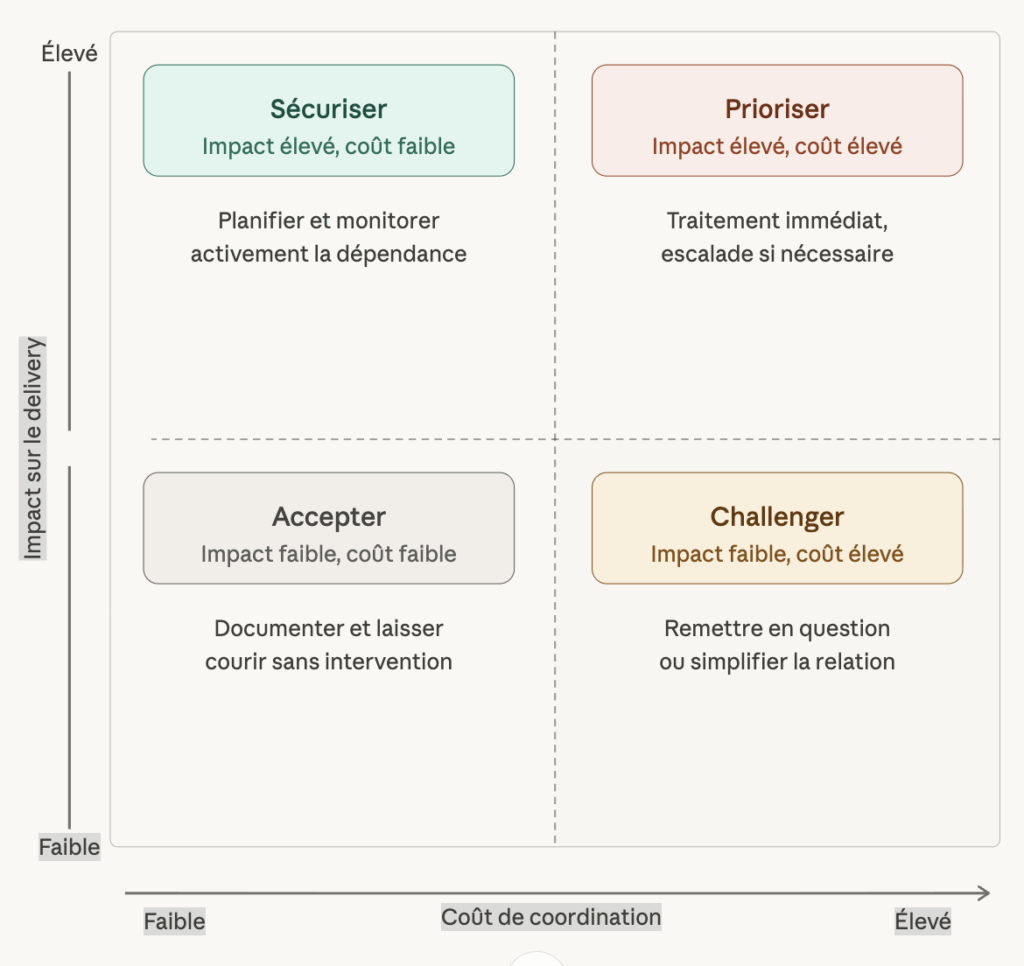
Cette matrice permet de distinguer plusieurs cas de figure. Certaines dépendances doivent être traitées immédiatement, parce qu’elles ont un impact élevé sur le delivery et un coût de coordination important. D’autres doivent surtout être sécurisées, parce qu’elles sont critiques mais encore relativement simples à gérer. D’autres, au contraire, méritent d’être challengées si leur coût de coordination semble disproportionné par rapport à leur impact réel. Enfin, certaines peuvent simplement être documentées sans mobiliser d’effort particulier. L’intérêt de cette lecture n’est pas de complexifier la priorisation, mais de la rendre plus réaliste.
Mieux piloter les dépendances sans tomber dans le “tout outil”
Bien sûr, rendre les dépendances visibles reste indispensable. Un lien entre tickets, une roadmap qui fait apparaître les points de blocage, une cartographie simple des dépendances critiques : tout cela aide à objectiver le sujet et à éviter les mauvaises surprises trop tardives.
Mais il faut éviter un écueil fréquent : croire qu’une dépendance est pilotée parce qu’elle est documentée. Un ticket marqué “blocked by” ou une jolie vue roadmap ne règlent rien à eux seuls. Ils rendent le problème visible, ce qui est déjà utile, mais ils ne réduisent ni la friction ni la complexité.
Ce qu’il faut rendre visible
Ce qui mérite vraiment d’être explicité, ce ne sont pas seulement les relations entre tickets, mais les conditions de delivery elles-mêmes. De quoi ce sujet dépend-il exactement ? Quelle équipe ou quelle décision conditionne réellement l’avancement ? À quel moment du flux le blocage risque-t-il d’apparaître ? Quel contournement existe si cette dépendance ne se débloque pas à temps ?
Ces questions sont souvent plus utiles qu’une simple cartographie exhaustive.
L’idée n’est pas d’entrer dans un tutoriel Jira, mais simplement d’illustrer une chose : lorsqu’une dépendance est rendue visible, elle devient plus facile à discuter collectivement. On voit mieux ce qui bloque, ce qui dépend de quoi, et où se situe réellement le point de fragilité. En revanche, cette visibilité ne suffit jamais à elle seule.
Pourquoi un ticket bloquant ne règle rien à lui seul
Le vrai travail commence après l’identification. Il consiste à clarifier les responsabilités, aligner les temporalités, arbitrer plus tôt, simplifier un périmètre, ou parfois repenser le découpage du sujet. Dans certains cas, il faut accepter qu’un problème de dépendance ne se résoudra pas avec plus de coordination, mais avec moins d’interfaces.
C’est souvent là que les équipes produit gagnent en maturité. Elles arrêtent de considérer les dépendances comme un bruit de fond inévitable du delivery, et commencent à les lire comme des signaux. Non pas seulement des signaux de blocage, mais des signaux de design organisationnel, de qualité de cadrage et de faisabilité réelle.
Ce que font différemment les équipes les plus fluides
Les équipes qui délivrent avec le moins de friction ne sont pas forcément celles qui vont le plus vite. Ce sont souvent celles qui ont appris à limiter les dépendances critiques, à les repérer plus tôt et à les intégrer dans leurs arbitrages.
1. Anticiper plus tôt
Elles ne découvrent pas les points de blocage en plein sprint ou au moment de la recette. Elles les font émerger dès le cadrage, lorsqu’il est encore possible de redécouper, de re-séquencer ou de renoncer à certaines hypothèses.
2. Découper autrement
Elles savent aussi qu’un sujet prioritaire n’a pas besoin d’être traité d’un seul bloc. Lorsqu’une fonctionnalité concentre trop de dépendances, elles cherchent une première version autonome, testable et livrable, plutôt que de maintenir artificiellement un périmètre complet mais irréaliste.
3. Réduire les dépendances critiques
Enfin, elles ne considèrent pas toutes les dépendances comme une fatalité. Lorsqu’un même type de blocage revient sans cesse, elles interrogent la structure qui le produit : les interfaces entre équipes, la répartition des responsabilités, ou le rôle de certains composants partagés.
Ce réflexe est important, parce qu’il déplace le sujet. On ne cherche plus seulement à mieux suivre les dépendances existantes. On cherche aussi à en produire moins à l’avenir, ou au moins à réduire celles qui pèsent le plus lourd sur le delivery.
Les dépendances comme signal de maturité produit
Au fond, le sujet dépasse largement la gestion de projet. Maîtriser les dépendances, ce n’est pas seulement mieux suivre les blocages. C’est mieux comprendre le système dans lequel un produit évolue, et voir plus tôt ce qui conditionne réellement la livraison de valeur. C’est aussi accepter qu’un bon arbitrage produit ne repose pas uniquement sur la valeur métier ou sur l’effort de développement, mais sur la capacité réelle d’une organisation à délivrer dans un environnement contraint. À ce titre, les dépendances sont un bon révélateur de maturité. Elles montrent où une organisation reste trop fragmentée, trop opaque ou trop dépendante de ses propres interfaces. Elles rappellent aussi qu’une roadmap ambitieuse ne vaut que si les conditions de delivery qui la sous-tendent ont été pensées avec le même sérieux.
Sources :
– Linking Modular Architecture to Development Teams, Martin Fowler.
– Maximizing Developer Effectiveness, Martin Fowler.
– Key Concepts, Team Topologies.
– Project dependencies, Atlassian.


